From Correlation to Causation through stories and math
Correlation and causation are two concepts that people often mixup in their minds. I must admit that I myself have been guilty about this, and it unlikely that I would ever entirely grow out of it as it is wired deeply into our psychology. Let me use this article to briefly emphasise what the concepts of correlation and causation means, some interesting stories that have emerged from people misunderstanding these concepts and an algorithm that attempts to find causal relationship using correlation information.
Here is a story that I heard a professor of mine, Prof. Dr. Ernst-Jan Camiel Wit, tell us during a lecture. There was a school that was involved in a study to see if providing free mid-day meals to students, which they could choose to be subscribed to this or not. At the end of the study, both the students who subscribed to it and did not where tested for different health indicators. It was observed that the students who chose to have meals from the programme had poorer health indicators.
In this example, one could be tempted to conclude that the mid-day meal programme may have caused this issue. Some may believe that the people higher up in the chain may have been corrupt and stole from the pot, whereas some others may believe that the funds provided were not sufficient. But the actual cause of this was that most students who did not choose to enrol in the programme believed that students who are less fortunate should benefit from this programme more, and hence most of the students who enrolled in the programme were otherwise poor. In other words, students who enrolled in the programme were not likely to have other sources of food, and they may have relied solely on the programme, whereas the students who did not enroll had plenty of other options to provide themselves with the required nutrients.
Here is another story from somewhere in North America in the eighteenth or nineteenth century. There were certain female people who lived in towns and cities with a certain coloured cat. At some point, there were certain diseases that affected everyone except these women, then people assumed that they were doing some dark magic to cause this, called them witches and often hunted them down. Sighting their cat was considered a bad omen as well. Now we know that the diseases were actually spread by rats and these women were safe because their cats ate the rats and prevented further spread of diseases to their owners.
There are several stories like such where people tend to associate correlation with causation. Indeed, if Event A causes Event B, the correlation between Event A and Event B would be high. However, if the correlation between Event C and Event B are high, that does not necessarily mean that Event C causes event B or viseversa.
There are also interesting scenarios where the direction of causality are misunderstood. Generally when we observe events such as the road being wet and rain falling, we do not assume that the wet road caused the rain to fall. However, I recently came to read an article stating that accummulation of cholestrol in the arteries are to ameliorate some damagest with the arteries; that is, they do not cause the issues with the arteries, rather they attempt to solve the issues with the arteries. Please do note that I am not a medical professional, nor a builogist; I simply attempt to make myself informed as I love the process, and it is possible that I may miss a thing or two while at it.
Now, it is easy to collect data and observe correlations between different variables. My favourite way of doing this is using a method called partial correlation. It measures the degree of association between two random variables, with the effect of a set of controlling random variables removed. If X represents a column that states how much it rained and Y represents a column that states how much rise in the lake nearby was observed, then the partial correlation is defined as:
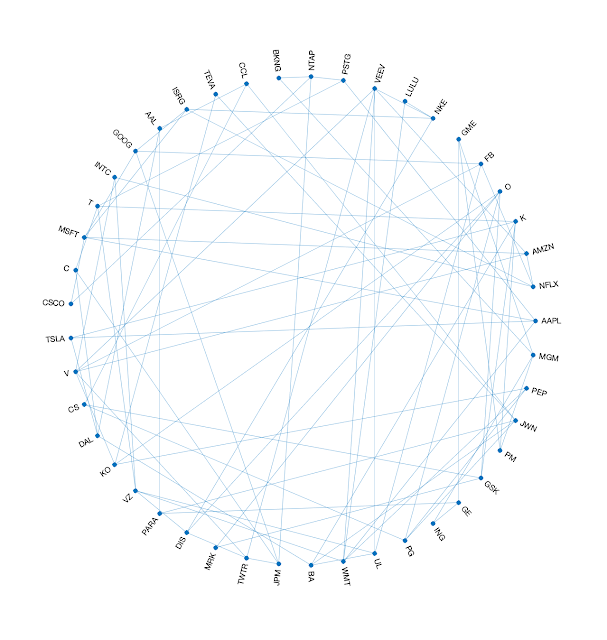
As we have already discussed, arriving at causal direction between different correlations is hard. Generally, we need to extensively study and evaluate to know what exactly is happening to know what the causal direction is. However, there is an algorithm I am familiar with that attempts to find the direction of causality, called PC Algorithm.
- Create an undirected graph that represents conditional dependence or correlation between different fields (like the graph you saw earlier).
- Apply causal orientation rules, which are:
- Collider rule
If nodes Xi and Xj are connected to Xk, and Xi is independent of Xj, then the direction of causality would point from Xi to Xk and Xj to Xk. - Consistency rules
These include avoiding cycles, avoiding new colliders and other inconsistencies that we can logically determine. Avoiding new collider means that if nodes Xi and Xj are connected to Xk and Xl, then we do not create a new collider with Xl. Rather, we would connect Xi to Xk, Xj to Xk, and Xk to Xl.



Comments
Post a Comment